
Are you sure your C# lists work as fast as they could? You might be surprised: even simple List<T> operations can slow down your application if not used wisely. Today, I will show you real-world, battle-tested techniques to make your lists fly. I’ll explain not just the “how” but the “why” behind each example.
Ready? Let’s boost your C# performance!
Initialize Lists with a Defined Capacity
When you anticipate the number of elements a list will contain, initializing it with a predefined capacity can prevent multiple memory reallocations and enhance performance.
Why It Matters:
By default, a List<T> starts with a small capacity and doubles its size each time it reaches capacity. This resizing involves allocating new memory and copying existing elements, which can be costly in terms of performance.
Example:
int expectedItems = 1000;
List<int> numbers = new List<int>(expectedItems);Personal Insight:
In one of my projects, failing to set the initial capacity led to noticeable lag during bulk data processing. Once I specified the capacity, the performance improved significantly.
Now let’s measure with BenchmarkDotNet the speed of working with a list with and without pre-initialization of the list capacity.
public class BenchmarkListCapacity
{
[Params(100, 5000, 20000)]
public int count;
[Benchmark]
public void AddToList()
{
List<int> list = new List<int>();
for (int i = 0; i < count; i++)
{
list.Add(i);
}
}
[Benchmark]
public void AddToListWithCapacity()
{
List<int> list = new List<int>(count);
for (int i = 0; i < count; i++)
{
list.Add(i);
}
}
}Result:
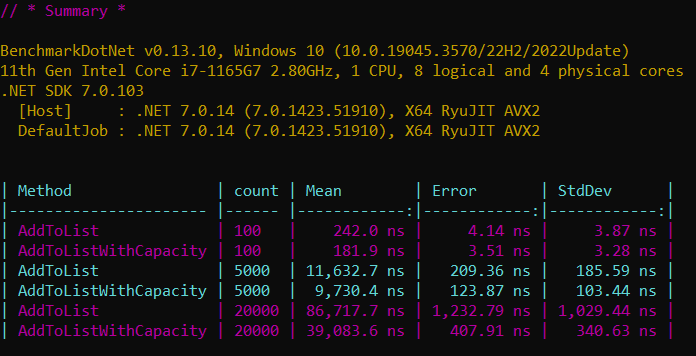
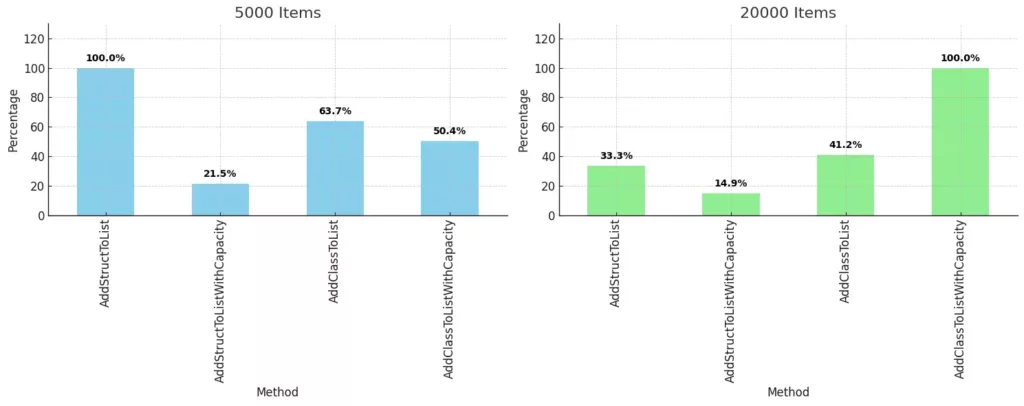
As you can see from the diagram, setting the capacity on average decrease the time of adding items to the list by from 20 to 55 percent, regard of the list size.

Remember, the Capacity of a List<T> is different from its Count property. Count indicates the actual number of elements in the list, whereas Capacity is about the potential number of elements it can hold before resizing.
Use AddRange() for Bulk Additions
Adding multiple items individually using the Add() method can be inefficient. Instead, use AddRange() to add a collection of items at once.
Why It Matters:
AddRange() reduces the overhead of multiple capacity checks and potential resizes, leading to better memory management and improved performance.
Example:
List<int> numbers = new List<int>();
int[] newNumbers = { 1, 2, 3, 4, 5 };
numbers.AddRange(newNumbers);Let’s now measure the speed of working with a list using the Add() and AddRange() methods.
public class BenchmarkListAddRange
{
private List<int> _items;
[Params(5000, 20000)]
public int count;
[GlobalSetup]
public void Setup()
{
_items = Enumerable.Range(1, count).ToList();
}
[Benchmark]
public void AddToList()
{
List<int> list = new List<int>();
for (int i = 0; i < _items.Count; i++)
{
list.Add(i);
}
}
[Benchmark]
public void AddRangeToList()
{
List<int> list = new List<int>();
list.AddRange(_items);
}
}Result:
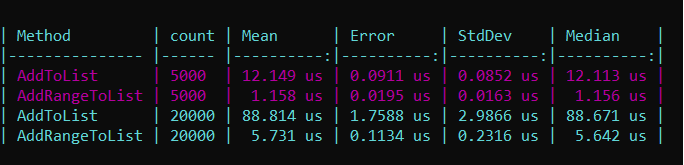
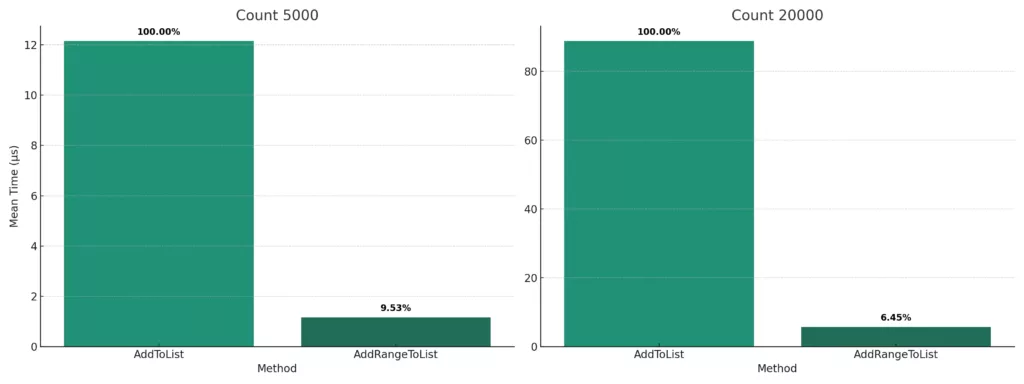
Benchmarking showed that using AddRange() was approximately 90% faster than multiple Add() calls when adding 5,000 items.
Choose the Right Data Structure
While List<T> is versatile, sometimes other data structures like LinkedList<T>, HashSet<T>, or Dictionary<TKey, TValue> may offer better performance for specific operations.
Why It Matters:
Selecting the appropriate data structure can lead to more efficient data manipulation and retrieval, tailored to your specific use case.
Example:
If you need fast lookups and unique items, a HashSet<T> might be more suitable than a List<T>.
Personal Insight:
In a caching mechanism I developed, switching from a list to a dictionary reduced lookup times drastically.
Let’s test the efficiency of utilizing a list with struct and class:
public class BenchmarkListStructAndClass
{
[Params(5000, 20000)]
public int count;
[Benchmark]
public void AddStructToList()
{
List<ItemStruct> list = new List<ItemStruct>();
for (int i = 0; i < count; i++)
{
list.Add(new ItemStruct());
}
}
[Benchmark]
public void AddStructToListWithCapacity()
{
List<ItemStruct> list = new List<ItemStruct>(count);
for (int i = 0; i < count; i++)
{
list.Add(new ItemStruct());
}
}
[Benchmark]
public void AddClassToList()
{
List<ItemClass> list = new List<ItemClass>();
for (int i = 0; i < count; i++)
{
list.Add(new ItemClass());
}
}
[Benchmark]
public void AddClassToListWithCapacity()
{
List<ItemClass> list = new List<ItemClass>(count);
for (int i = 0; i < count; i++)
{
list.Add(new ItemClass());
}
}
}Result:
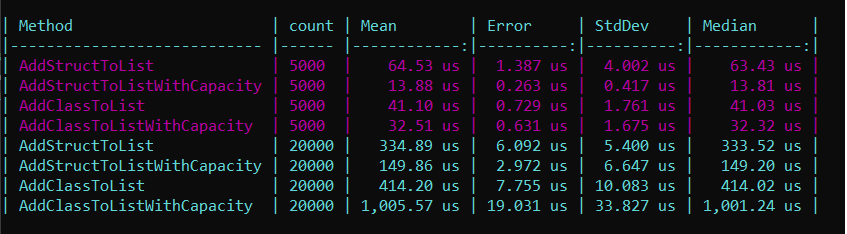
And diagram of result:
Use Count Property Over Any() for Emptiness Checks
When checking if a list is empty, prefer using the Count property over the Any() method.
Why It Matters:
Count is a property, while Any() is a method. Accessing a property is generally faster than invoking a method.
Example:
// Preferred
if (numbers.Count == 0) { /* Handle empty list */ }
// Less efficient
if (!numbers.Any()) { /* Handle empty list */ }Let’s see how fast Count and Any() work:
public class BenchmarkListAnyAndCount
{
private List<int> _items;
[Params(20000)]
public int count;
[GlobalSetup]
public void Setup()
{
_items = Enumerable.Range(1, 10000).ToList();
}
[Benchmark]
public void CheckEmptyByCount()
{
for (int i = 0; i < count; i++)
{
if (_items.Count > 0)
{
}
}
}
[Benchmark]
public void CheckEmptyByAny()
{
for (int i = 0; i < count; i++)
{
if (_items.Any())
{
}
}
}
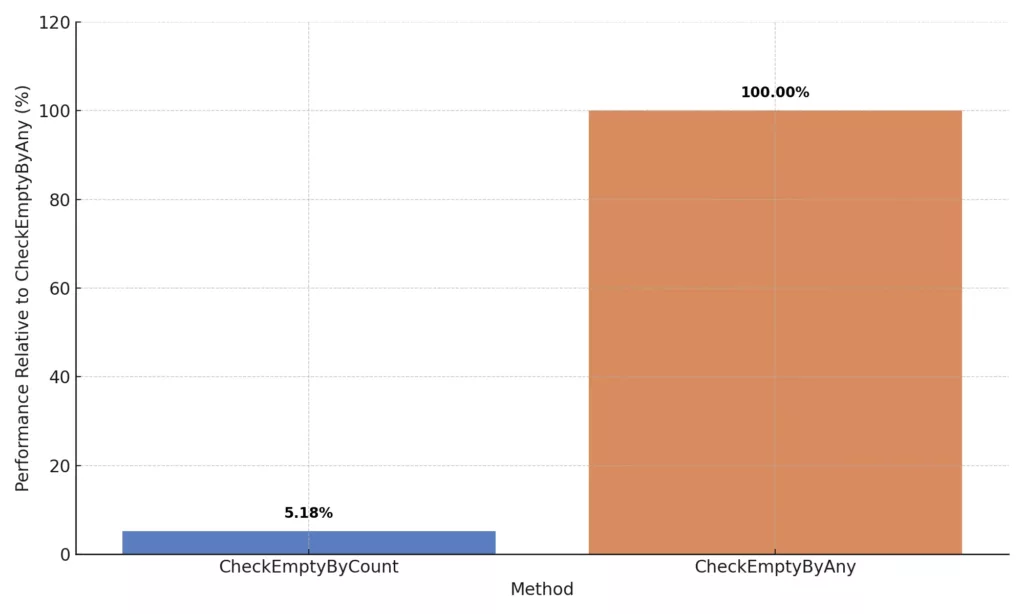
}Result:

In micro-benchmarks, Count > 0 was consistently faster than !Any(), especially in tight loops.
Prefer foreach Over for Loops for Iteration
When iterating over a list without needing the index, foreach can be more readable and, in some cases, more efficient than a for loop.
Why It Matters:
foreach abstracts the iteration logic and can lead to cleaner code. The compiler can also optimize foreach loops effectively.
Example:
// Preferred
foreach (var number in numbers)
{
Console.WriteLine(number);
}
// Less readable
for (int i = 0; i < numbers.Count; i++)
{
Console.WriteLine(numbers[i]);
}Personal Insight:
I once refactored a series of for loops to foreach, which not only improved readability but also reduced the potential for off-by-one errors.
Let’s take a look at how work loop foreach and for:
public class BenchmarkListForeachAndFor
{
private List<ItemClass> _items;
[Params(2000000)]
public int count;
[GlobalSetup]
public void Setup()
{
_items = Enumerable.Range(1, count)
.Select(x => new ItemClass { ItemId = x })
.ToList();
}
[Benchmark]
public void CheckForeach()
{
int sum = 0;
foreach (var item in _items)
{
sum += item.ItemId;
}
}
[Benchmark]
public void CheckFor()
{
int sum = 0;
for (int i = 0; i < _items.Count; i++)
{
sum += _items[i].ItemId;
}
}
}Result:
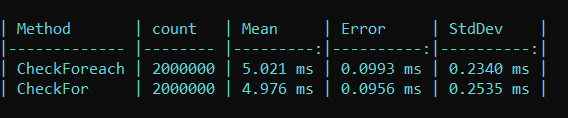
Utilize BinarySearch for Sorted Lists
For sorted lists, using BinarySearch can significantly speed up search operations compared to linear searches.
Why It Matters:
BinarySearch has a time complexity of O(log n), making it much faster for large datasets compared to O(n) for linear searches.
Example:
List<int> sortedNumbers = new List<int> { 1, 3, 5, 7, 9 };
int index = sortedNumbers.BinarySearch(5);
if (index >= 0)
{
Console.WriteLine("Item found at index: " + index);
}
else
{
Console.WriteLine("Item not found. Nearest index: " + ~index);
}Let’s see the difference in performance between a normal search and using the BinarySearch method:
public class BenchmarkListBinarySearch
{
private List<int> _items;
private int _findValue;
[Params(50000)]
public int count;
[GlobalSetup]
public void Setup()
{
_items = Enumerable.Range(1, count).ToList();
var random = new Random();
_findValue = random.Next(count);
}
[Benchmark]
public void CheckBinarySearch()
{
int index = _items.BinarySearch(_findValue);
}
[Benchmark]
public void CheckFirst()
{
int index = _items.First(x => x == _findValue);
}
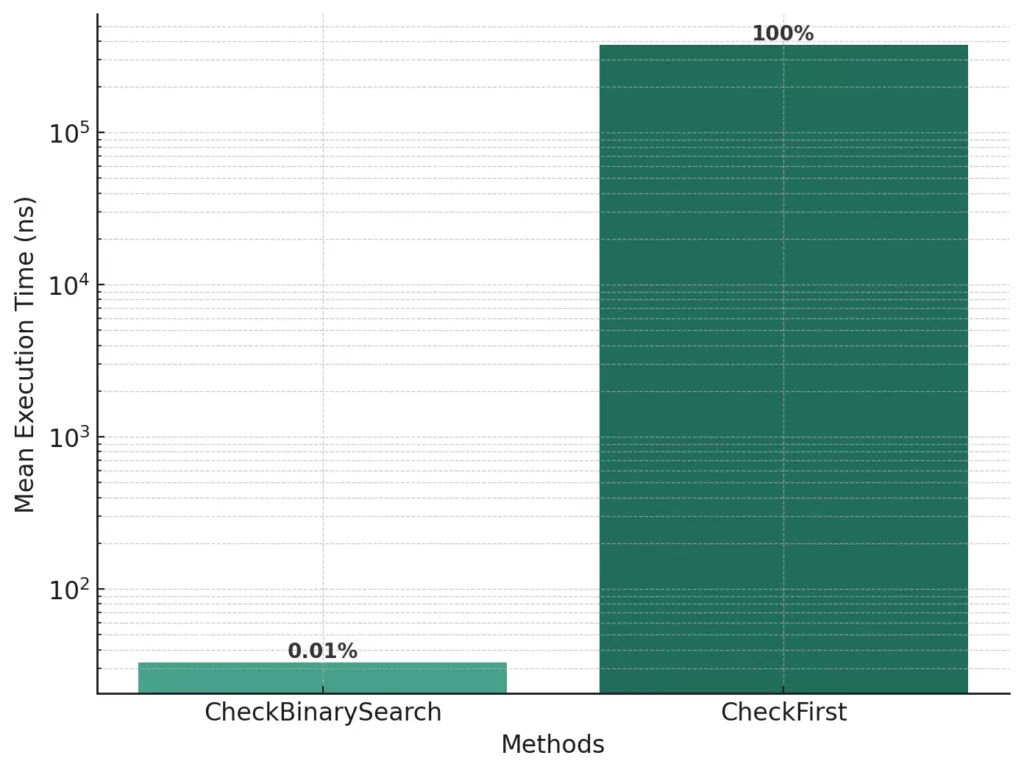
}Result:
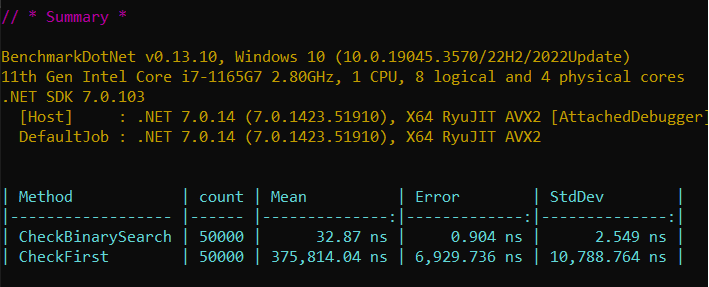
In a dataset of 50,000 sorted items, BinarySearch located elements over 100 times faster than a linear search using First().
FAQ: Enhancing C# List Performance
Set the initial capacity when you have a reasonable estimate of the number of elements the list will contain. This approach minimizes the overhead of dynamic resizing.
AddRange() always better than multiple Add() calls?Generally, yes. AddRange() is more efficient for adding multiple items at once, as it reduces the number of resizing operations.
List<T> and other data structures?Consider the operations you’ll perform most frequently. For example, use Dictionary<TKey, TValue> for fast lookups by key, HashSet<T> for unique items, and Queue<T> or Stack<T> for specific access patterns.
Count == 0 preferred over !Any()?Accessing the Count property is faster than invoking the Any() method, leading to slight performance gains, especially in performance-critical sections.
Conclusion: Make Your Lists Fly
As we’ve seen, optimizing lists in C# is all about anticipation and measurement. By allocating smartly, avoiding unnecessary overhead, and benchmarking wisely, you ensure your applications remain smooth and fast. Start applying these techniques today and feel the difference in your app’s responsiveness!
Question for you: Have you encountered surprising performance issues with lists in your projects? Share your experience in the comments!
Great job explaining the differences between Add() and AddRange(). The examples made it super clear.